
Cost-effective Approach for ML Model Deployment
Content by: Gaurav Mittal
I recently spearheaded the deployment of an ML model on AWS Lambda, significantly reducing our dependency on costly third-party deployment tools. Previously, our team utilized a licensed deployment tool that charged for API calls made to input data into the ML model and retrieve predictions. These API call charges added substantial overhead to operational costs, making the process unsustainable.
To overcome this issue, I explored solutions to bring the ML model deployment in-house. AWS Lambda emerged as the best choice due to its serverless architecture and pay-per-use pricing model. By leveraging Lambda, we ensured that costs were incurred only when the model was invoked, eliminating the need for ongoing infrastructure or licensing expenses.
I have configured the Lambda function to get invoke through API gateway and thus was able to handle inference requests seamlessly, integrating it into our existing workflows without disrupting any downstream systems.
The result was a highly cost-effective deployment pipeline that not only reduced operational expenses but also allowed for greater flexibility and scalability. This initiative demonstrated the value of combining serverless technologies with strategic in-house development to optimize costs and operational efficiency. the I found a cost-effective solution for deploying the ML model using AWS Lambda. With this approach, my organization only pays for the service when it is used, avoiding the cost of deployment tools. In the end, we saved money by building the ML model ourselves and using the most cost-effective deployment method: AWS Lambda.
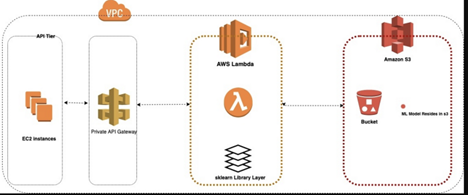
In this article, I’ll walk you through steps to deploy a ML model on AWS Lambda. AWS Lambda is a preferred choice because it is inexpensive and automatically scalable, and we only pay for the requests we make. This approach involves loading the ML model from an S3 bucket, generating a AWS layer for python libraries – sklearn and pandas.
Technical Implementation
For this approach, deploy the ML model as a pickle file in an S3 bucket and using it through a Lambda API makes the process simple, scalable, and cost-effective. First, the model is trained and saved as a pickle file, which is uploaded to an S3 bucket for secure and centralized storage. AWS Lambda is set up to load this model from S3 when needed, enabling quick predictions without requiring a dedicated server. When someone calls the API connected to the Lambda function, the model is fetched, run, and returns predictions based on the input data. This serverless setup ensures high availability, scales automatically, and saves costs since you only pay when the API is used. To make the ML model work, you can create a Lambda layer with required libraries like scikit-learn and pandas, making it easy to load and use the model.
Making it Time effective
I was receiving the response for first call in 10–12 secs and for following calls it took less than a sec.
Though Lambda approach is cost effective, however for the first call, if Lambda Container is not running, when Lambda function is invoked, it must download Lambda Container in Lambda Runtime Environment which is a time-consuming process and will add on to the overall response time.
So, is it possible to make Lambda approach time effective from the very first call?
YES!!! It certainly is.
You can do so by adding a Lambda Trigger- a CloudWatch event to keep lambda warm. Now instead of downloading the model during api call, it would make the ML model always available. It could also be configured to run during a particular time duration e.g., business hours or non-business hours.
Conclusion
In conclusion, deploying an ML model using AWS Lambda provides a scalable, cost-effective solution that eliminates the need for expensive licensing and deployment tools. The above approach discussed—reading the ML model from an S3 bucket demonstrate flexibility in addressing different deployment scenarios. While the Lambda architecture is efficient, addressing the cold start latency with techniques like warming up the Lambda function ensures consistent performance, even for the first API call. By combining cost efficiency and performance optimization, this deployment method stands out as a practical choice for organizations aiming to maximize value and reduce expenses.
References
https://aws.amazon.com/premiumsupport/knowledge-center/lambda-layer-simulated-docker/
https://docs.aws.amazon.com/AmazonCloudWatch/latest/events/RunLambdaSchedule.html